Proyección inversa
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
from sklearn.neighbors import NearestNeighbors
from sklearn.metrics import pairwise_distances
from numpy.linalg import norm
from deap import base, creator, tools, algorithms
import warnings
warnings.filterwarnings("ignore")1. Importación de elementos¶
def visualizar_RS(df_sel):
y_test = df_sel['SSPL']
y_pred = df_sel['SSPL_pred']
# Asume que ya tienes: y_test (Series), y_pred (array-like), pred_obj (float)
plt.scatter(y_test, y_pred, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], "r--")
plt.xlabel("SSPL real")
plt.ylabel("SSPL predicho")
plt.title("Predicción vs Realidad")
plt.tight_layout()
plt.show()2. Carga de datos y revisión básica de calidad¶
Para la implementación de FUCO en primer lugar es necesario realizar la carga del conjunto de datos. En este caso, se hace uso del conjunto de datos AirfoilSelfNoise.csv l cual es un conjunto de datos de la NASA obtenido a partir de una seri de pruebas aerodinámicas y acústicas de secciones de álabes aerodinámicos bidimensionales y tridimensionales, realizadas en un túnel de viento anecoico. Es por esto que se pasa a realizar la carga del conjuto de datos en el entorno:
# Se realiza la carga de los datos
df = pd.read_csv("AirfoilSelfNoise.csv", sep=',')3. Modelado¶
Como paso previo a la implementación de FUCO, es necesario tener un modelo de regresión en el entorno. En esta implementación se ha obtado por entrenar un modelo de regresión lineal que se encargue de predección la variable SSPL a partir del resto de variables existentes en el conjunto de datos. Para esta implementación se ha decidido no optimizar mediante hiperparámetros el modelo ya que esta implementación no busca rendimiento sino la capacidad de mostrar la implementación y funcionamiento del framework. Se pasa a realizar el entrenamiento del modelo:
# Selección de variables
X = df.drop(columns=["SSPL"])
y = df["SSPL"]
# División en conjunto de train y test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Creación y entrenamiento del modelo
modelo_no_t_bl = LinearRegression()
modelo_no_t_bl.fit(X_train, y_train)
# Predicciones
y_pred = modelo_no_t_bl.predict(X_test)
# Evaluación del modelo
coeficientes = pd.Series(modelo_no_t_bl.coef_, index=X_train.columns)
print("Intercepto:", modelo_no_t_bl.intercept_)
print("\nCoeficientes:")
print(coeficientes)
# Cálculo de error cuadrátrico y R2
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("----------------------------------------------------")
print("MSE:", mse)
print("R²:", r2)
print("----------------------------------------------------")
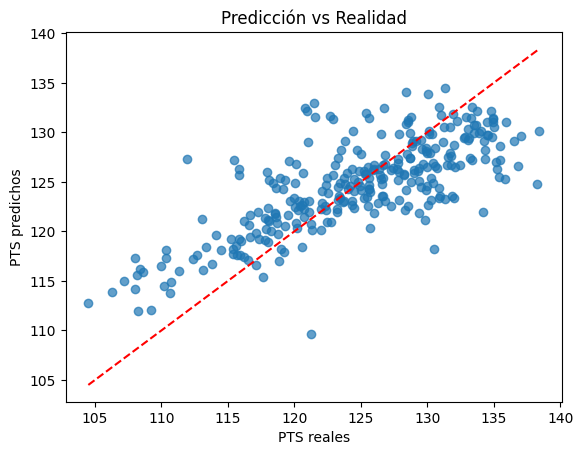
plt.scatter(y_test, y_pred, alpha=0.7)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], "r--")
plt.xlabel("PTS reales")
plt.ylabel("PTS predichos")
plt.title("Predicción vs Realidad")
plt.show()Intercepto: 132.5315974058017
Coeficientes:
f -0.001272
alpha -0.405660
c -34.469438
U_infinity 0.098021
delta -139.460274
dtype: float64
----------------------------------------------------
MSE: 22.128643318247306
R²: 0.5582979754897279
----------------------------------------------------
4. FUCO¶
A través de este apartado, se realiza la implementación de FUCO. Para ello, en primer lugar, se realiza la división del espacio de respuesta a partir del la observación fáctica seleccionada y los umbrales de epsilon y delta definidos. Posteriormente, se realiza la generación de las alteración de la observación que en este caso serán mediante Proyección inversa. Estas alteraciónes de la observación será evaluadas mediante diferentes propiedades para comprobar cuales de ellas son las mejores para construir explicaciones contrafácticas. Por último, se realizará la construcción de las explicaciones.
4.1 División del espacio de respuesta¶
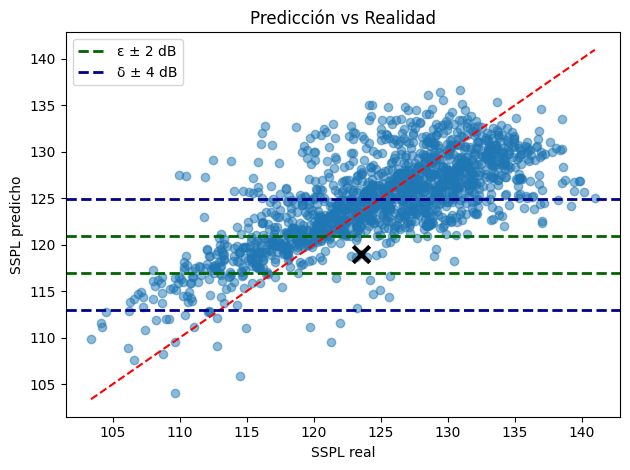
Como primer paso se realiza la divisón del espacio de respuesta. Para ello, es necesario seleccionar una observación a analizar la cual en nuestro caso es la 1487. Posteriormente, se definen los umbrales y se realiza el filtrado del conjunto de datos para la construcción de los Response sets:
# Se calcula las predicciones del modelo para los regisros
df['SSPL_pred'] = modelo_no_t_bl.predict(X)
# Se selecciona el resgistro objetivo sobre el que se calcularan los contrafácticos
print("----------- OBSERVACIÓN ORIGINAL -----------")
pred_obj = 123.514
print(df[df['SSPL']==pred_obj])
# Se definen los umbrales de epsilon y delta que dividiran el espacio de respuesta
epsilon_u_y = pred_obj + 2
epsilon_l_y = pred_obj - 2
delta_u_y = pred_obj + 6
delta_l_y = pred_obj - 6
# Se divide el espacio de respuesta
df_RF = df[(df['SSPL_pred'] <=epsilon_u_y) & (df['SSPL_pred'] >= epsilon_l_y)].reset_index().drop('index',axis=1)
df_RCF = df[((df['SSPL_pred'] >=epsilon_u_y) & (df['SSPL_pred'] <= delta_u_y)) | ((df['SSPL_pred'] <=epsilon_l_y) & (df['SSPL_pred'] >= delta_l_y))].reset_index().drop('index',axis=1)
df_FCF = df[(df['SSPL_pred'] >=epsilon_u_y) | (df['SSPL_pred'] <= epsilon_l_y)].reset_index().drop('index',axis=1) ----------- OBSERVACIÓN ORIGINAL -----------
f alpha c U_infinity delta SSPL SSPL_pred
1487 200 15.6 0.1016 39.6 0.052849 123.514 118.958208
Se realiza la visualización de la división del espacio de respuesta:
y_test = df['SSPL']
y_pred = df['SSPL_pred']
# Asume que ya tienes: y_test (Series), y_pred (array-like), pred_obj (float)
plt.scatter(y_test, y_pred, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], "r--")
y_pred_arr = np.asarray(y_pred)
i = df[df['SSPL']==pred_obj].index[0]
x_obj = y_test.iloc[i] # SSPL real correspondiente
y_obj = y_pred_arr[i] # SSPL predicho (cerca de pred_obj)
# Se definen los umbrales de epsilon y delta que dividiran el espacio de respuesta
epsilon_u_y = y_obj + 2
epsilon_l_y = y_obj - 2
delta_u_y = y_obj + 6
delta_l_y = y_obj - 6
plt.scatter([x_obj], [y_obj], marker="x", s=140, linewidths=3, color = 'black')
# Colores distintos
epsilon_color = "darkgreen"
delta_color = "darkblue"
plt.axhline(y=epsilon_u_y, linestyle="--", linewidth=2, color=epsilon_color, label="ε ± 2 dB")
plt.axhline(y=epsilon_l_y, linestyle="--", linewidth=2, color=epsilon_color)
plt.axhline(y=delta_u_y, linestyle="--", linewidth=2, color=delta_color, label="δ ± 4 dB")
plt.axhline(y=delta_l_y, linestyle="--", linewidth=2, color=delta_color)
plt.xlabel("SSPL real")
plt.ylabel("SSPL predicho")
plt.title("Predicción vs Realidad")
plt.legend()
plt.tight_layout()
plt.show()
4.2 Generación de observaciones candidatas¶
Para la generación de las observaciones candidatas, en este caso se ha seleccionado el método de Proyección inversa. Este método consisten en generar nuevas observaciones a partir de valores objetivo en el espacio de respuesta y proyectarlos posteriormente hacia el espacio de características.
Adicionalmente en esta sección, se realiza la construcción de las métricas de evaluación. En nuestro caso para FUCO han sido selecciónadas la validez, la proximidad, la robustez y la plausbilidad. Con estas variables se puede conocer a las alteraciones de la observación desde diferentes puntos de vista.
# 1º CREACIÓN DE OBSERVACIONES: Se generan las observaciones alteradas a partir de la observación factual
# Instancia factual:
df_factual = df[df['SSPL']==pred_obj].copy()
print("----------- OBSERVACIÓN FACTICA -----------")
print(df_factual)----------- OBSERVACIÓN FACTICA -----------
f alpha c U_infinity delta SSPL SSPL_pred
1487 200 15.6 0.1016 39.6 0.052849 123.514 118.958208
# Definición del entorno
x_factual = df_factual.iloc[0] # vector de referencia
accionables = ['f', 'alpha', 'c', 'U_infinity', 'delta']
inmutables = [] # si hay alguna, por ejemplo 'age', 'gender', etc.
# Entrenamiento previo del modelo KNN sobre datos reales
real_data = df[accionables]
knn_model = NearestNeighbors(n_neighbors=5)
knn_model.fit(real_data)
# Factual vector para calcular proximidad
x_factual_vector = x_factual[accionables].values4.2.1 Definir la región de salida deseada¶
# Se selecciona el resgistro objetivo sobre el que se calcularan los contrafácticos
print("----------- OBSERVACIÓN ORIGINAL -----------")
pred_obj = 123.514
print(df[df['SSPL']==pred_obj])
# Se definen los umbrales de epsilon y delta que dividiran el espacio de respuesta
epsilon_u_y = pred_obj + 2
epsilon_l_y = pred_obj - 2
delta_u_y = pred_obj + 6
delta_l_y = pred_obj - 6 ----------- OBSERVACIÓN ORIGINAL -----------
f alpha c U_infinity delta SSPL SSPL_pred
1487 200 15.6 0.1016 39.6 0.052849 123.514 118.958208
# Función: Comprueba si la predicción se encuentra dentro de RCF
def is_valid_RCF(y_pred):
return (epsilon_l_y >= y_pred >= delta_l_y) or (epsilon_u_y <= y_pred <= delta_u_y)
4.2.2 Definir el espacio de búsqueda¶
accionables = ['f', 'alpha', 'c', 'U_infinity', 'delta']
# Valores discretos permitidos
f_values = df['f'].unique()
c_values = df['c'].unique()
u_values = df['U_infinity'].unique()
n_samples = 1000
np.random.seed(42)
# Crear observaciones candidatas
df_proj_inv = pd.DataFrame({
'f': np.random.choice(f_values, n_samples),
'alpha': np.random.uniform(df['alpha'].min(), df['alpha'].max(), n_samples),
'c': np.random.choice(c_values, n_samples),
'U_infinity': np.random.choice(u_values, n_samples),
'delta': np.random.uniform(df['delta'].min(), df['delta'].max(), n_samples)
})
4.2.3 Prefecir y filtrar por la región objetivo¶
# Predecir SSPL
df_proj_inv['SSPL_pred'] = modelo_no_t_bl.predict(df_proj_inv)
# Filtrar solo los que caen en la región deseada
df_proj_inv = df_proj_inv[
df_proj_inv['SSPL_pred'].apply(is_valid_RCF)
].reset_index(drop=True)
4.2.4 Evaluación¶
Se realiza la construcción de las métricas de evaluación
4.2.4.1 Proximidad¶
# Convertir factual a array
x_factual_array = np.array(x_factual[accionables]).reshape(1, -1)
obs_array = df_proj_inv[accionables].values
# Distancias
df_proj_inv['proximidad_L1'] = pairwise_distances(obs_array, x_factual_array, metric='manhattan')4.2.4.2 Plausibidad¶
# Entrenamiento con datos reales (sin columna target)
real_data = df[accionables].values
knn_model = NearestNeighbors(n_neighbors=1).fit(real_data)
# Distancia al vecino más cercano real
df_proj_inv['plausibilidad_knn'] = knn_model.kneighbors(obs_array, return_distance=True)[0].flatten()
4.2.4.3 Robustez¶
def estimate_robustness(row, model, n_perturb=5, noise=0.01):
X = row.copy()
perturbations = pd.DataFrame([X + np.random.normal(0, noise, size=X.shape) for _ in range(n_perturb)],
columns=accionables)
preds = model.predict(perturbations)
return np.std(preds)
# Aplicar fila a fila
df_proj_inv['robustez'] = df_proj_inv[accionables].apply(
lambda row: estimate_robustness(row, modelo_no_t_bl), axis=1
)4.3 Análisis de resultados obtenidos¶
Para seleccionar los mejores contrafácticos, se realiza la utilización de un Frente de Pareto que es una estructura que permite la evaluación multiobjetivo. En nuestro caso, utilizaremos el frente de Pareto la ordenación de las métricas de evaluación según su proximidad, plausibidad y robustez de manera descendente. Con esto los contrafácticos serán seleccionados mediante la proximidad en primer lugar, la plausibidad en segundo y la robustez finalmente. Se realiza la construcción del frente:
df_pareto = df_proj_inv[['plausibilidad_knn', 'robustez', 'proximidad_L1']].round(2)
df_pareto.head()4.3.1 Resumen estadístico general¶
Se extraen de cada una las propiedades del frente estadísticas para su comparación con otros métodos:
print("----------- VOLUMETRÍA -----------")
print(df_pareto.shape)
print("\n----------- MEDIAS -----------")
print(df_pareto.mean())
print("\n----------- DESVIACION -----------")
print(df_pareto.std())----------- VOLUMETRÍA -----------
(352, 3)
----------- MEDIAS -----------
plausibilidad_knn 0.72821
robustez 1.17017
proximidad_L1 1660.83804
dtype: float64
----------- DESVIACION -----------
plausibilidad_knn 1.067597
robustez 0.426437
proximidad_L1 2034.485540
dtype: float64
4.3.2 Ordenación del frente de pareto¶
Se realiza la ordenación del frente de pareto:
df_pareto_sorted = df_pareto.sort_values(
by=["proximidad_L1", "plausibilidad_knn", "robustez"],
ascending=[True, True, True]
)
df_pareto_sorted.head(10)4.4 Generación de explicaciones¶
Para finalizar se realiza la generación de explicación. Para nuestro caso seleccionaremos las 5 alteraciones de la observación ordenadas anterirometne y se construirá una explicación con ellas en formato texto garantizando el traslado de conocimiento al usuario que lo lea:
# --------- 0) Helpers ----------
def _find_col(df, candidates):
for c in candidates:
if c in df.columns:
return c
return None
PROX_CANDIDATES = ["proximidad_L1", "proximity_L1", "proximity", "prox", "L1"]
PLAUS_CANDIDATES = ["plausibilidad_knn", "plausibility_knn", "plausibility", "plaus", "knn_mean_dist"]
ROB_CANDIDATES = ["robustez", "robustness", "rob", "pred_std", "std_pred"]
# --------- 1) Factual ----------
x_factual = df_factual.iloc[0].copy()
# Si no existe "accionables", intentar inferirlas
try:
_ = accionables
except NameError:
# intentamos inferir a partir de df_proj_inv o df_obs_*
accionables = None
# --------- 2) Construir un dataframe "df_rank" que tenga variables + métricas ----------
if "df_proj_inv" in globals():
df_rank = df_proj_inv.copy()
else:
# Caso alternativo: df_pareto (métricas) + df_obs_* (variables)
if "df_pareto" not in globals():
raise ValueError("No encuentro df_proj_inv ni df_pareto. Necesito el frente de Pareto para ordenar.")
# Busca automáticamente un df con observaciones (variables) que comparta índice con df_pareto
candidates_obs = ["df_obs_pi", "df_obs_proy", "df_obs_proy_inv", "df_obs", "df_candidates", "df_alteraciones"]
df_obs = None
for name in candidates_obs:
if name in globals():
tmp = globals()[name]
if isinstance(tmp, pd.DataFrame) and tmp.index.equals(df_pareto.index):
df_obs = tmp
break
if df_obs is None:
raise ValueError(
"No existe df_proj_inv y no he podido encontrar un DataFrame de observaciones "
"(por ejemplo df_obs_pi) con el mismo índice que df_pareto."
)
df_rank = df_obs.join(df_pareto, how="inner")
# --------- 3) Inferir accionables si falta ----------
if accionables is None:
# Intersección entre factual y df_rank quitando métricas
metric_cols = set(PROX_CANDIDATES + PLAUS_CANDIDATES + ROB_CANDIDATES)
accionables = [c for c in df_rank.columns if (c in df_factual.columns) and (c not in metric_cols)]
if not accionables:
raise ValueError("No he podido inferir 'accionables'. Define la lista accionables manualmente.")
# --------- 4) Detectar columnas de métricas ----------
col_prox = _find_col(df_rank, PROX_CANDIDATES)
col_plaus = _find_col(df_rank, PLAUS_CANDIDATES)
col_rob = _find_col(df_rank, ROB_CANDIDATES)
missing = [name for name, col in [("proximidad", col_prox), ("plausibilidad", col_plaus), ("robustez", col_rob)] if col is None]
if missing:
raise ValueError(
f"No encuentro columnas de métricas en el frente para: {missing}. "
f"Columnas disponibles: {list(df_rank.columns)}"
)
# --------- 5) Ordenar y TOP-5 ----------
df_pareto_sorted = df_rank.sort_values(
by=[col_prox, col_rob, col_plaus],
ascending=[True, True, True]
).copy()
top5 = df_pareto_sorted.head(5).copy()
# --------- 6) Predicción factual (opcional) ----------
y_factual = None
try:
Xf = pd.DataFrame([x_factual[accionables].values], columns=accionables)
y_factual = float(modelo_no_t_bl.predict(Xf)[0])
except Exception:
pass
# --------- 7) Función de explicación ----------
def generar_explicacion_cf(x_fact, x_cf, variables, prox, plaus, rob, decimals=4, y_fact=None, model=None):
cambios = []
for v in variables:
if v not in x_fact.index or v not in x_cf.index:
continue
a = x_fact[v]
b = x_cf[v]
# Evitar falsos cambios por precisión
if isinstance(a, (float, np.floating)) or isinstance(b, (float, np.floating)):
if abs(float(a) - float(b)) < 10**(-decimals):
continue
a_fmt = f"{float(a):.{decimals}f}" if isinstance(a, (float, np.floating)) else str(a)
b_fmt = f"{float(b):.{decimals}f}" if isinstance(b, (float, np.floating)) else str(b)
cambios.append(f"- {v}: {a_fmt} → {b_fmt}")
cambios_txt = "\n".join(cambios) if cambios else "No se detectan cambios en las variables consideradas."
# Predicción del CF (opcional)
y_cf = None
if model is not None:
try:
Xcf = pd.DataFrame([x_cf[variables].values], columns=variables)
y_cf = float(model.predict(Xcf)[0])
except Exception:
pass
metrics_txt = f"proximidad={prox:.4f}, robustez={rob:.4f}, plausibilidad={plaus:.4f}"
pred_txt = ""
if (y_fact is not None) and (y_cf is not None):
pred_txt = f"\nPredicción: {y_fact:.4f} → {y_cf:.4f}"
return (
f"Explicación contrafáctica ({metrics_txt})\n"
f"Si modificas la observación original aplicando los siguientes cambios, "
f"la observación pasaría a pertenecer a la región RCF:\n"
f"{cambios_txt}"
f"{pred_txt}\n"
)
# --------- 8) Generar explicaciones TOP-5 ----------
explicaciones = []
for i, (_, row) in enumerate(top5.iterrows(), start=1):
prox = float(row[col_prox])
plaus = float(row[col_plaus])
rob = float(row[col_rob])
texto_i = generar_explicacion_cf(
x_fact=x_factual,
x_cf=row,
variables=accionables,
prox=prox,
plaus=plaus,
rob=rob,
decimals=4,
y_fact=y_factual,
model=modelo_no_t_bl
)
explicaciones.append(f"CF #{i}\n{texto_i}")
explicaciones_texto = ("\n" + "-" * 60 + "\n").join(explicaciones)
print(explicaciones_texto)CF #1
Explicación contrafáctica (proximidad=1.0546, robustez=1.2575, plausibilidad=0.8010)
Si modificas la observación original aplicando los siguientes cambios, la observación pasaría a pertenecer a la región RCF:
- alpha: 15.6000 → 16.6027
- delta: 0.0528 → 0.0010
Predicción: 118.9582 → 125.7851
------------------------------------------------------------
CF #2
Explicación contrafáctica (proximidad=5.1537, robustez=1.5602, plausibilidad=0.6362)
Si modificas la observación original aplicando los siguientes cambios, la observación pasaría a pertenecer a la región RCF:
- alpha: 15.6000 → 10.5281
- c: 0.1016 → 0.0508
- delta: 0.0528 → 0.0219
Predicción: 118.9582 → 127.0788
------------------------------------------------------------
CF #3
Explicación contrafáctica (proximidad=5.5675, robustez=1.0997, plausibilidad=1.0540)
Si modificas la observación original aplicando los siguientes cambios, la observación pasaría a pertenecer a la región RCF:
- alpha: 15.6000 → 21.1488
- delta: 0.0528 → 0.0341
Predicción: 118.9582 → 119.3217
------------------------------------------------------------
CF #4
Explicación contrafáctica (proximidad=6.0407, robustez=0.5980, plausibilidad=0.5788)
Si modificas la observación original aplicando los siguientes cambios, la observación pasaría a pertenecer a la región RCF:
- alpha: 15.6000 → 21.6265
- delta: 0.0528 → 0.0386
Predicción: 118.9582 → 118.4988
------------------------------------------------------------
CF #5
Explicación contrafáctica (proximidad=6.0618, robustez=1.7999, plausibilidad=0.5982)
Si modificas la observación original aplicando los siguientes cambios, la observación pasaría a pertenecer a la región RCF:
- alpha: 15.6000 → 21.6028
- c: 0.1016 → 0.0508
- delta: 0.0528 → 0.0446
Predicción: 118.9582 → 119.4203