Introducción a FUCO
En esta sección nosotros vamos a explicar el FUCO framework, un acercamiento que permite la generación de CE en problemas de regresión. Este framework provee de las herramientas necesarias para la división del espacio de respuesta, donde las predicciones del modelo están distribuidas, permitiendo así la definición de sets of predictions según las restricciones y limitaciones definidas por los stakeholders. En esta introducción serán definidos los aspectos claves para el entendimiento de FUCO. Adicionalmente se incluyen los notebooks en lo que se muestra la implementación del framework con tres métodos diferentes de generación de explicaciones.
Problem setup/Notation¶
El diseño de nuestro framework está enfocado en la generación de CFs en un modelo de regresión que predice el valor de una instancia dentro del feature space cuya predicción será definida como . Dentro de este modelo, la obtención de \glspl{CF} es realizada mediante la selección de la observación cuya predicción es conocida como en el espacio de respuesta.
Según la definición formal, un CF es aquella observación definida como que corresponde con una versión alterada de . En donde para saber que es relevante para , es elegida minimizando la distancia con según una función :
Para nosotros, un CF es definido como aquella observación en la que la distancia entre su predicción con respecto a sea mínima y los cambios a realizar en sean plausibles y accesibles teniendo en cuenta las restricciones y limitaciones definidas por los stackeholders del modelo. Las restricciones y limitaciones son representadas en el espacio de respuesta mediante dos umbrales: 1) Umbrales de Epsilon () que representa las restricciones definidas por el dueño o gestor del modelo y, 2) Umbrales de Delta () que representan las restricciones definidas por el beneficiario de las predicciones del modelo. Estos umbrales son definidos de manera superior e inferior tomando como referencia la observación siguiendo la notación y para los límites superiores y, y para los inferiores sobre el espacio de respuesta.
La definición de los umbrales permite realizar la división del espacio de respuesta en Response sets que son regiones del espacio de respuesta en las que las observaciones son distribuidas. Estas regiones son: 1) Reasonable Factuals (RF) que es la región donde las observaciones se encuentran contenidas por los umbrales y , 2) Fuzzy Counterfactuals (FCF) que es la región donde las observaciones se encuentran excluidas por los umbrales y y, 3) Reasonable Counterfactuals (RCF) que es la región donde se encuentran las observaciones contenidas por los umbrales y en la parte superior y y inferior del espacio de respuesta. A modo ilustrativo, el espacio de respuesta es dividido de la siguiente manera:
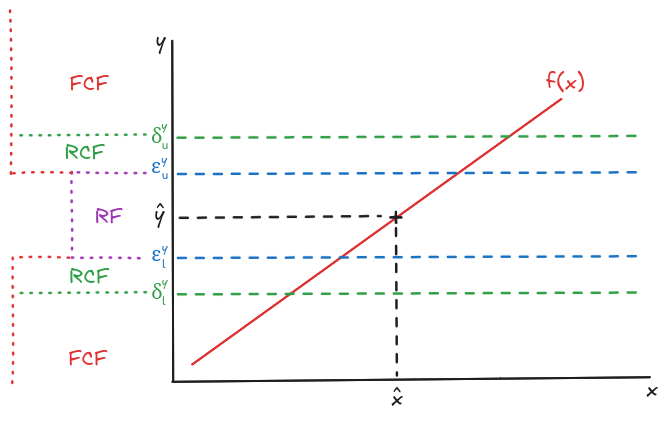
Figure 1:Representación ilustrativa del espacio de respuesta de un modelo de regresión lineal (), que muestra la distribución del ejemplo factual junto con los umbrales superiores e inferiores (azul) y (verde). Además, cada una de las regiones del espacio de respuesta se representa visualmente en el espacio de salida.
Definición de umbrales¶
La definición de umbrales dentro del FUCO framework es fundamental para la estructura de las RS, ya que permite identificar las regiones en el espacio de respuesta al mismo tiempo que se tienen en cuenta las restricciones de los stakeholders del modelo. Es por esto que en el FUCO framework, la definición de los umbrales ϵ y δ permite a los stakeholders del modelo definir las regiones en las que serán distribuidas las respuestas de las observaciones. Por un lado, la definición de ϵ se realiza directamente sobre la variable de respuesta y debe establecerse siempre, ya que este umbral permite diferenciar qué observaciones son consideradas como CF. Por otro lado, la definición de δ se realiza sobre las variables que conforman el feature space y no siempre puede establecerse, ya que en ciertos casos el actor no puede definir limitaciones.
En cuanto a la definición de los umbrales de ϵ, estos pueden ser establecidos por el dueño del modelo, que es la persona encargada de su diseño, o por el gestor del modelo, que es quien hace uso del mismo. Estos umbrales pueden definirse siguiendo distintos criterios, como el conocimiento del dominio por parte de los actores, donde ambos umbrales son asignados manualmente; mediante la parametrización durante el entrenamiento del modelo o a partir de su error; o mediante un intervalo de confianza cuando los umbrales no son asignados directamente por el dueño o el gestor del modelo.
Respecto a los umbrales de δ, estos son establecidos por el cliente del modelo, que es el actor afectado por las decisiones del mismo. Para establecer estos umbrales, dado que las restricciones se definen sobre las variables del feature space, una vez definidas deben proyectarse sobre la variable de respuesta con el fin de determinar dichos umbrales. La asignación de las restricciones sobre las variables puede realizarse de forma manual por parte del actor, identificando aquellas limitaciones que considere más críticas —especialmente cuando el modelo cuenta con un gran número de variables— o mediante la utilización de intervalos de confianza sobre dichas variables.
Otro aspecto fundamental para la obtención de las RS es la combinación de los umbrales definidos por los actores del modelo. Este aspecto adquiere gran relevancia, ya que tras la definición de los umbrales pueden darse distintos escenarios que dificulten la selección de las RS.
El primer escenario ocurre cuando los umbrales de ϵ están contenidos dentro de δ, lo que permite identificar las RS de forma clara. El segundo escenario aparece cuando los umbrales de δ no han sido definidos o están contenidos dentro de los umbrales de ϵ; en este caso, únicamente se podrán identificar dos de las tres RS. El tercer y último escenario se produce cuando el umbral superior o inferior de δ está contenido dentro de los umbrales de ϵ; en esta situación, las RS se identifican sin tener en cuenta el umbral que se encuentra contenido.
Response sets¶
Para detectar los CF, FUCO divide el espacio de respuesta en regiones llamadas RS mediante los umbrales de y . Estas RS agrupan las observaciones cuyas predicciones tienen valores similares. Esta forma de agrupar permite generar los CF considerando las restricciones y limitaciones de los stakeholders del modelo. Esta forma de dividir el espacio de respuesta permite obtener tres tipos diferentes de RS que son: 1) RF, 2) FCF y 3) RCF.
La región RF es aquella que es definida por los umbrales y , conteniendo las observaciones cuyas predicciones son más cercanas a la observación original. Dentro de esta región, las observaciones contenidas son identificadas como semifactuals debido a que, a nivel de modelo, las predicciones de las observaciones son indistinguibles unas de otras y, a nivel de usuario, los valores predichos pueden ser considerados equivalentes ya que se encuentran dentro de las restricciones establecidas por el dueño o gestor del modelo. Por último, la definición formal de RF es la siguiente:
La región FCF es aquella que se encuentra excluida por los umbrales y , conteniendo las observaciones cuyas predicciones son las más lejanas a la observación original. Dentro de esta región, las observaciones son consideradas como fuzzy counterfactuals debido a que se encuentran fuera de las restricciones definidas por el dueño o gestor del modelo. Sin embargo, estas observaciones son técnicamente consideradas como CF, aunque no lo suficientemente útiles al no satisfacer las limitaciones impuestas por el dueño o gestor del modelo. Es por este motivo que, si los valores del umbral fueran diferentes, las observaciones podrían ser agrupadas dentro del conjunto RCF. Además, en ciertos contextos donde el conjunto RCF se encuentra vacío, estas observaciones pueden ser aceptadas como CF debido a que representan las opciones más cercanas disponibles a la observación original. Por último, la definición formal de FCF es la siguiente:
La región RCF es aquella que se encuentra contenida por los umbrales y dentro de la región FCF. Dentro de esta región, las observaciones son consideradas como fuzzy counterfactuals ya que están contenidas en la región FCF, y como counterfactuals debido a que se encuentran en una región donde los cambios son aceptados por los stakeholders del modelo. Estas observaciones son consideradas como CF debido a que en el espacio de respuesta son las más útiles para obtener cambios en las variables más accesibles para los actores del modelo, al encontrarse dentro de sus restricciones y limitaciones. Además, RCF representa el negotiation space, que es la región donde las observaciones son consideradas difusas. Que las observaciones sean consideradas difusas significa que deben ser evaluadas para conocer qué tan bien funcionan como CF. Por último, la definición formal de RCF es la siguiente:
Evaluación de CF¶
La evaluación de las observaciones se presenta dentro del framework FUCO como un aspecto clave, ya que permite identificar qué observaciones pueden ser utilizadas como CF. Como se explicó anteriormente, la definición de las RS permite diferenciar entre observaciones consideradas semifactuals, fuzzy counterfactuals y counterfactuals. Esta diferenciación se realiza a partir del valor que toma la predicción de cada observación dentro del espacio de respuesta y de su cercanía con la observación original.
Esta cercanía se calcula mediante medidas de distancia, como la distancia euclidiana, lo que permite identificar qué observaciones, en términos de su predicción, se encuentran más próximas a la observación original. Sin embargo, considerar únicamente los valores de la predicción y su cercanía con la observación original no permite determinar si las observaciones son representativas y realistas, ya que los cambios propuestos en las variables podrían ser inalcanzables para los usuarios.
Por este motivo, de manera habitual la evaluación de las observaciones se realiza comprobando si los cambios propuestos cumplen determinadas propiedades, como la validez, la causalidad o el realismo. No obstante, muchas de estas propiedades no son totalmente compatibles entre sí, por lo que a menudo es necesario sacrificar el cumplimiento de algunas para obtener otras. Por ejemplo, existe un conflicto entre proximidad y plausibilidad, ya que imponer realismo puede dificultar la obtención de cambios mínimos en las variables; también entre robustez, plausibilidad y proximidad, donde los métodos que logran gran robustez suelen producir cambios poco realistas o cercanos; o entre plausibilidad y validez, donde algunos cambios pueden ser válidos para el modelo pero irreales en el mundo real.
Debido a estas limitaciones, el framework FUCO centra la evaluación en analizar las observaciones de cada RS de manera individual con el fin de identificar las más representativas. Esta evaluación se realiza comparando cada observación con la observación original mediante cuatro propiedades: plausibilidad, proximidad y robustez. El análisis conjunto de estas propiedades permite obtener una visión completa de los cambios propuestos por cada observación y facilita la identificación de las más representativas dentro de cada región.
La plausibilidad es la propiedad que permite evaluar si los valores de los atributos de una observación son coherentes con los de la población a la que pertenece. Esto permite determinar si los cambios son realistas, es decir, si se asemejan a ejemplos existentes y respetan las correlaciones observadas entre variables. En la práctica, la plausibilidad puede formalizarse calculando la distancia promedio entre la observación y sus vecinos más cercanos dentro del conjunto de datos reales, de modo que la observación permanezca dentro de una región densa del espacio de datos. En el framework FUCO, la plausibilidad se mide comparando las variables de la observación con las de sus vecinos mediante métricas estadísticas de cada variable, con el objetivo de comprobar si los valores se encuentran dentro de rangos coherentes.
La proximidad es la propiedad que mide cuánto se parece una observación a la observación original. Formalmente, se calcula mediante una función de distancia, donde la diferencia entre la observación original y las observaciones candidatas debe ser pequeña, generalmente menor que un umbral predefinido. Las funciones de distancia más utilizadas son L1 y L2, que también son empleadas en el framework FUCO para medir la cercanía entre observaciones.
Por último, la robustez es la propiedad que permite evaluar si pequeños cambios en el modelo afectan a la predicción de una observación. En otras palabras, mientras las variaciones sean mínimas, la predicción debería mantenerse similar. En el framework FUCO, la robustez se evalúa realizando múltiples ejecuciones del modelo y comparando el porcentaje de observaciones que continúan perteneciendo a la misma RS.
Mediante la evaluación conjunta de estas cuatro propiedades se obtiene una visión global del comportamiento de cada observación, lo que permite identificar aquellas cuyos cambios con respecto a la observación original son más representativos y realistas dentro de cada una de las RS.
Para el análisis de los valores obtenidos se hará uso de un Frente de Pareto, que es el conjunto de soluciones no dominadas en un problema de optimización multiobjetivo, donde ninguna solución puede mejorar en uno de los objetivos sin empeorar al menos en otro. Este frente representa el conjunto de alternativas óptimas que establecen diferentes compromisos entre los objetivos considerados, permitiendo seleccionar aquellas soluciones que mejor equilibran los criterios evaluados.
Generación de explicaciones¶
La presentación de los cambios al usuario constituye el aspecto final dentro del framework FUCO, ya que permite indicar qué modificaciones debe realizar el usuario en una observación para obtener una predicción diferente. Desde que se popularizó el uso de los CF, la generación de buenas explicaciones se ha convertido en un elemento fundamental para obtener CE, ya que estas buscan responder a preguntas del tipo: “¿Qué cambios tendría que hacer en X para cambiar la predicción de la clase A a la clase B?”. En el framework FUCO se centra en generar explicaciones que permitan a los stakeholders del modelo adaptar la información proporcionada según las necesidades del usuario final. Para ello, FUCO presenta las explicaciones en un formato interpretativo del tipo:
“Si el valor de la variable 1 fuese Y y el de la variable 2 fuese Z, la observación pasaría a pertenecer al conjunto FCF.”
Este formato permite identificar de forma clara qué variables deben modificarse para producir un cambio en la predicción. La selección de las variables que deben modificarse puede realizarse de dos maneras. Por un lado, los stakeholders del modelo pueden definir manualmente qué variables son más relevantes y cuáles pueden omitirse, utilizando su conocimiento del dominio para ofrecer explicaciones más adaptadas a las necesidades del usuario final. Por otro lado, cuando estas variables no se definen explícitamente, el framework utiliza CFI con el objetivo de proporcionar explicaciones en las que las variables a modificar se determinen automáticamente en función de su importancia en la generación de los CF.